2022. 1. 30. 00:27ㆍTIL💡/Database
회사에서 과제로 SQL Server를 학습해야해서 개인적으로 퇴근 후 실습을 수행하였다.
다만 SQL Server가 Mac용으로 릴리스되지 않아서 대체재로 Docker의 Azure SQL로 데이터베이스 서버 역할을 수행하도록 하였다.
1. 데이터베이스 만들기
--- 새 데이터베이스 만들기
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TutorialDB'
)
CREATE DATABASE [TutorialDB]
GO
--- 쿼리 저장소 기능 사용
ALTER DATABASE [TutorialDB] SET QUERY_STORE=ON
GO그 결과 아래 데이터베이스가 생성된 것을 확인할 수 있었다.

이전에 데이터베이스에 대해 열심히 공부하지 않았을 때는, 데이터베이스 = 테이블이라고 착각했다.
하지만 데이터베이스에는 테이블 외에도 View, SP(저장 프로시저), 인덱스 등 DB 오브젝트들이 저장되거나 참조된다.
2. 테이블 만들기
USE [TutorialDB]
--- 테이블 만들기
CREATE TABLE Employees
(
Id int PRIMARY KEY IDENTITY,
[Name] nvarchar(50),
Email NVARCHAR(50),
Department NVARCHAR(50)
)이 쿼리를 실행하면 아래와 같이 테이블이 생성된다.

3. 데이터 삽입
--- 행 수를 나타내는 메시지가 결과 집합의 일부로 반환되지 않도록 설정
SET NOCOUNT ON
--- 테이블 데이터 삽입
DECLARE @counter int = 1
WHILE(@counter <= 100)
BEGIN
DECLARE @Name NVARCHAR(50) = 'ABC' + RTRIM(@counter)
DECLARE @Email NVARCHAR(50) = 'abc' + RTRIM(@counter) + '@pragimtech.com'
DECLARE @Dept NVARCHAR(10) = 'Dept' + RTRIM(@counter)
INSERT INTO Employees values (@Name, @Email, @Dept)
SET @counter = @counter + 1
IF(@counter%100 = 0)
PRINT RTRIM(@counter) + 'rows inserted'
END
4. Index 확인
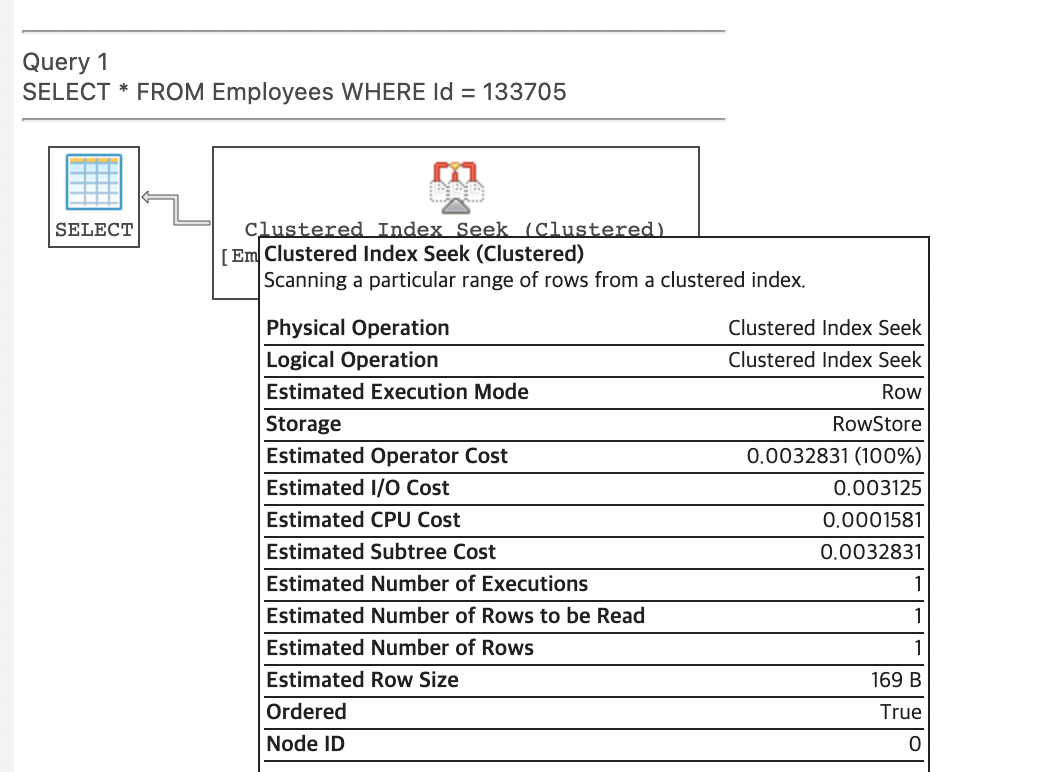
예시로 간단한 SELECT 문을 실행한 후 Execution Plan을 확인하였다.
Index가 적용되는 Id를 기준으로 SELECT문을 실행하였다.
SELECT * FROM Employees WHERE Id = 133705;
Clustered Index Seek로 실행되었고, Employee의 Id가 Index로 작용하였다.
인덱스를 활용한 덕분에 읽은 Row가 총 1개뿐이다. 즉 효율적이다.
반면, 인덱스가 아닌 컬럼으로 SELECT를 실행하면 Estimated Number of Rows to be Read가 달라진다.
SELECT * FROM Employees WHERE Name = 'ABC89';그리고 위에서는 Clustered Index Seek을 수행했던 것과 다르게 Clustered Index Scan을 수행하는 것을 확인할 수 있다.

이를 개선하고자 Name 컬럼을 기준으로 비클러스터링 인덱스를 생성했다.
--- 비클러스터링 인덱스 만들기
CREATE NONCLUSTERED INDEX IX_Employees_Name
ON [dbo].[Employees] ([Name]);
이를 적용해 두 번째 SELECT를 재실행한다.
SELECT * FROM Employees
WITH(INDEX (IX_EMployees_Name))
WHERE Name = 'ABC89';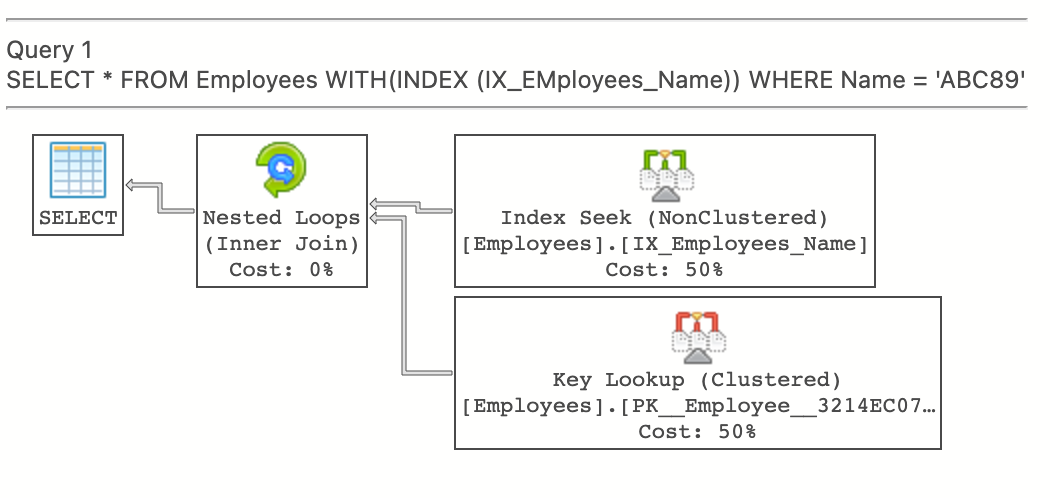

비클러스터링 인덱스는 클러스터링 인덱스와 다르게 Key-Value 형식으로 Row Locator들을 분류한다.
Row Locator는 마치 책 맨 뒷장의 찾아보기 같다.
Row Locators
| Name | EmployeeId |
| Alexa | 932 |
| Becky | 421 |
| Charlie | 212 |
여기서 EmployeeId를 찾아서 데이터베이스에서 클러스터링 인덱스를 기준으로 빠르게 해당 Row를 찾아낸다.
그래서 위 SELECT에서 비클러스터링 인덱스를 기준으로 특정 rows들을 스캔하는 Index Seek를 먼저 수행하고, 그 다음 EmployeeId를 발견했으니 클러스터링 인덱스를 기준으로 Key Lookup을 수행한다.
성능 비교


갑자기 예상 외로 비클러스터링 인덱스를 사용한 경우가 Cost가 더 들었다.(즉 비효율적)
알고보니 이 경우에는 row가 100개로 데이터 수가 적어서 오히려 비클러스터형 인덱스가 더 비효율적으로 작동했다.
row를 700개로 만드니 그 때부터 비클러스터형 인덱스의 Cost가 클러스터형 인덱스보다 적게 들었고, 별도로 인덱스를 설정하지 않으면 자동으로 비클러스터형 인덱스로 설정이되어서 SELECT 실행이 이루어짐을 확인했다.
참조
'TIL💡 > Database' 카테고리의 다른 글
| [Redis] 데이터타입 실습2 (0) | 2022.02.27 |
|---|---|
| [Redis] Redis 학습 및 데이터 타입 실습1 (0) | 2022.02.26 |
| [SQL Server] Transaction (0) | 2022.02.12 |
| [SQL Server] Lock (0) | 2022.02.08 |
| [데이터베이스] Index(인덱스) (0) | 2021.10.13 |