2022. 2. 27. 03:52ㆍTIL💡/Database

💚 Set
레디스에서의 셋은 순서가 없고 동일한 문자열이 없는 콜렉션이다.
따라서 셋에 동일한 엘리먼트를 계속 추가할 수 없다.
내부적으로 셋은 일부 커맨드(엘리먼트 추가 및 삭제, 검색의 성능 속도는 항상 O(1)다)를 최적화해야하기 때문에 해시 테이블로 구현됐다.
셋의 모든 엘리먼트 값이 정수면 셋의 메모리 영역은 줄어들고, 전체 엘리먼트 개수는 set-max-intset-entries 설정 값만큼 커질 수 있다.
셋이 가질 수 있는 엘리먼트의 최대 개수는 2^32 - 1이다.
(아무래도 셋의 개수가 unsigned int형으로 세팅되어 있나 보다.)
즉 한 셋에 40억개 이상의 엘리먼트를 저장할 수 있음을 의미한다.
사용 예시
✨ 데이터 필터링
주어진 한 도시에서 출발해서 다른 도시로 도착하는 모든 비행기 필터링
✨ 데이터 그룹핑
비슷한 제품을 보는 모든 사용자를 그룹핑하기
(예를 들면 아마존 웹사이트에서 추천하는 것)
✨엘리먼트십 확인
사용자가 블랙리스트에 있는지 확인하기
참고
https://thoughtbot.com/blog/redis-set-intersection-using-sets-to-filter-data
Redis Set Intersection - Using Sets to Filter Data
Redis is a fantastic lightweight key-value store. It also acts as a data...
thoughtbot.com
예제
- 음악 애플리케이션
- 모든 사용자는 선호하는 음악가 셋을 가진다.
- 한 사용자 계정에서 선호하는 가수를 추가 및 삭제하고, 두 사용자가 공통적으로 선호하는 가수를 찾으며 다른 사용자의 선호도를 기반으로 가수를 탐색한다.
SADD 커맨드는 셋에 하나 이상의 엘리먼트를 추가한다. 이는 셋에 이미 존재하ㅡㄴ 엘리먼트를 무시하고 추가된 엘리먼트 개수를 리턴한다.

SINTER 커맨드는 하나 이상의 셋을 받아 모든 셋에 공통으로 존재하는 엘리먼트를 배열로 리턴한다.

Max와 Hugo 두 사용자가 공통으로 선호하는 가수만 리턴한다.
SDIFF 커맨드는 하나 이상의 셋을 받는다.
첫 번째 셋의 모든 엘리먼트 중 그 뒤에 따르는 셋에 존재하지 않는 엘리먼트를 배열로 리턴된다.
SDIFF 커맨드에서 키 이름의 순서가 중요하다. SDIFF 커맨드의 결과에서 엘리먼트가 존재하지 않으면, 비어있는 셋으로 간주된다.

1) Hugo의 플레이리스트에는 존재하지 않고 Max의 플레이리스트에 존재하는 가수 이름 리턴
2) Max의 플레이리스트에는 존재하지 않고 Hugo의 플레이리스트에 존재하는 가수 이름 리턴

SUNION 커맨드는 하나 이상의 셋을 받는다.
모든 셋의 모든 엘리먼트를 하나의 배열로 모아 리턴한다.
리턴한 결과에는 중복된 엘리먼트가 존재하지 않는다.

SRANDMEMBER 커맨드는 셋에서 엘리먼트를 무작위로 뽑은 후 리턴한다.
셋은 순서가 없기 때문에 특정 위치에 존재하는 엘리먼트를 얻을 수 없다.

SISMEMBER 커맨드는 셋에 엘리먼트가 존재하는지 확인한다.
엘리먼트가 존재하면 1을 리턴하고, 엘리먼트가 존재하지 않으면 0을 리턴한다.
SREM 커맨드는 주어진 엘리먼트를 셋에서 삭제한 후, 셋에 남아있는 엘리먼트의 개수를 리턴
SCARD 커맨드는 셋의 엘리먼트 개수를 리턴
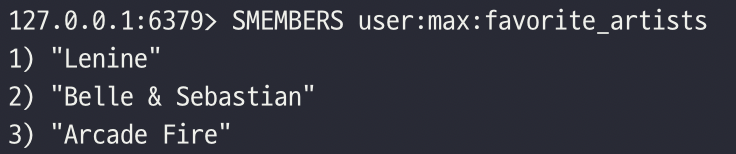
SMEMBERS 커맨드는 셋의 모든 엘리먼트를 배열로 리턴
💚 정렬된 셋
정렬된 셋은 셋과 비슷하지만 정렬된 셋의 모든 엘리먼트는 연관 점수를 가진다.
다시 말해 정렬된 셋은 점수로 정렬된 중복 문자열이 없는 콜렉션이다.
반복 점수를 가진 엘리먼트를 가질 수 있다. 이런 경우에 반복 엘리먼트를 사건 편집 순서대로 정렬할 수 있다.
정렬된 셋 커맨드는 빠른 편이지만 점수로 엘리먼트를 비교해야 하기 때문에 셋 커맨드보다 빠르지 않다.
정렬된 셋에서 엘리먼트의 추가 및 삭제, 변경 성능은 대수 시간 즉 O(log(N))며 여기서 N은 정렬된 셋의 엘리먼트 개수다.
정렬된 셋의 내부 구현은 2개의 분리된 데이터 구조로 돼 있다.
- 해시 테이블이 존재하는 Skiplist다.
Skiplist는 순서대로 정렬된 엘리먼트를 빠르게 검색할 수 있는 데이터 구조다.
- zset-max-ziplist-entries와 zset-max-ziplist-value설정을 기반으로 하는 Ziplist이다.
사용 예시
✨ 고객서비스에서 실시간 대기 목록 만들기
✨ 상위 점수를 가진 사용자, 비슷한 점수를 가진 사용자, 친구의 점수를 보여주는 큰 규모의 온라인 게임에서 리더보드 보여주기
실습
ZADD 커맨드는 정렬된 셋에 하나 이상의 엘리먼트를 추가한다.
ZADD 커맨드를 실행할 때 정렬된 셋에 엘리먼트가 이미 존재하면 해당 엘리먼트는 무시하고, 추가된 엘리먼트의 개수를 리턴한다.

엘리먼트를 점수와 문자열 값이 있는 정렬된 셋에 추가한다. 2가지 정렬 기준, 즉 엘리먼트 점수와 엘리먼트 값이 있다.
엘리먼트 점수에 동점이 발생하면 이런 동점을 없애기 위해 엘리먼트 값의 사전 편집 순 정렬을 사용한다.
실습
정렬된 셋에서는 범위를 읽어올 수 있는
- ZRANGE
낮은 점수에서 높은 점수로 엘리먼트를 리턴
여러 엘리먼트의 점수가 동점이면 사전 편집 순으로 오름차순 정렬을 사용
- ZRANGEBYINDEX
- ZRANGEBYSCORE
- ZREVRANGE
높은 점수에서 낮은 점수로 엘리먼트를 리턴
여러 엘리먼트의 점수가 동점이면, 사전 편집 순으로 내림차순 정렬을 사용
- ZREVRANGEBYINDEX
- ZREVRANGEBYSCORE
ZRANGE, ZREVRANGE 모두 키 이름과 시작 인덱스, 종료 인덱스를 받는다.
색인은 0 기반이고 양수 또는 음수 값을 가질 수 있다.
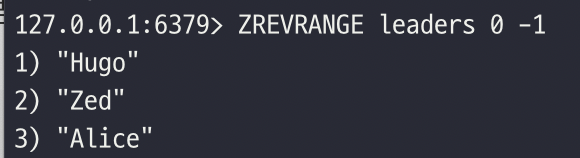
또한 WITHSCORES 키워드를 사용해 엘리먼트에 점수를 함께 리턴할 수 있는 매개변수를 옵션으로 전달 가능

ZREM 커맨드는 정렬된 셋에서 엘리먼트 삭제

ZSCORE 커맨드와 ZRANK/ZREVRANK 커맨드를 사용해 정렬된 셋에서 특정 엘리먼트의 등수 또는 점수를 읽어올 수 있다.
- ZSCORE: 엘리먼트의 점수를 리턴
- ZRANK: 등수가 낮은 순에서 높은 순으로 정렬된 엘리먼트 등수를 리턴
가장 낮은 점수를 가진 엘리먼트가 0순위
- ZREVRANK: 등수가 높은 순에서 낮은 순으로 정렬된 엘리먼트 등수를 리턴
가장 높은 점수를 가진 엘리먼트가 0순위
예제) 온라인 게임에서 리더보드 시스템 개발
기능
- 사용자 추가 및 삭제
- 사용자의 상세 정보 출력
- 상위 등수 사용자 표시
- 특정 사용자의 바로 위 등수와 바로 아래 등수 사용자 표시
💚 비트맵
비트맵은 레디스의 실제 데이터 타입이 아니다.
내부적으로 비트맵은 문자열이다.
비트맵은 문자열의 비트 연산자 집합이라고 말할 수 있다.
그러나 레디스는 문자열을 비트맵으로 제어할 수 있는 커맨드를 제공하기 때문에 비트맵을 데이터 타입으로 간주하고 진행할 것이다.
비트맵은 비트 배열 또는 비트셋으로도 알려진다.
비트맵은 개별 비트를 0 또는 1로 저장할 수 있는 비트열이다.
비트맵을 0과 1로 구성된 배열로 생각할 수 있다.
레디스 문서는 비트맵 인덱스를 오프셋(offset)으로 나타낸다.
| 오프셋 0 | 오프셋 1 | 오프셋 2 | 오프셋 3 | 오프셋 4 |
| 1 | 0 | 0 | 1 | 0 |
비트맵은 메모리 효율이 좋고 빠른 데이터 검색을 지원하며 2^32 비트까지 저장할 수 있다.
성능 비교
ex)특정 일자에 웹사이트를 방문한 모든 사용자의 ID를 저장하는 데 필요한 경우를 고려
| 레디스 키 | 데이터 타입 | 사용자당 비트 크기 | 저장된 사용자 | 전체 메모리 |
| visits:2015-01-01 | 비트맵 | 1비트 | 5백만 | 1 * 500000 bits = 625KB |
| visits:2015-01-01 | 셋 | 32비트(정수형) | 2백만 | 32 * 2000000 bits = 8MB |
비트맵 구현 시 전체 사용자 기반으로 메모리를 할당해야한다.
웹페이지를 방문하지 않은 사용자에게 메모리를 할당할 때에도 비트맵 구현은 셋 구현보다 메모리를 훨씬 더 적게 사용한다.
그러나 비트맵은 항상 메모리를 효율적으로 사용하지 않는다.
2백만명 대신 100명의 방문자만 생각한다면 최악의 시나리오가 발생할 수 있다.
| 레디스 키 | 데이터 타입 | 사용자당 비트 크기 | 저장된 사용자 | 전체 메모리 |
| visits:2015-01-01 | 비트맵 | 1비트 | 5백만 | 1 * 500000 bits = 625KB |
| visits:2015-01-01 | 셋 | 32비트(정수형) | 100 | 32 * 100 bits = 3,125KB |
비트맵은 사용자가 어떤 액션을 실행했는지 또는 얼마나 많은 이벤트가 발생했는지를 알려줄 수 있기 때문에
비트맵은 실시간 분석을 포함하는 애플리케이션에 매우 적합하다.
- 오늘 사용자 1은 'Redis 핵심 정리'를 읽었는가
- 이번 주에 사용자 1은 앵그리 버드 게임을 실행했는가
- 올해 앵그리 버드 게임을 몇 명의 사용자가 실행했는가?
실습
특정 날짜에 웹페이지를 방문했던 사용자의 ID를 저장하기 위 해 비트맨 커맨드 사용
일련의 숫자로 이루어진 ID로 각 사용자 식별한다.
각 비트맵 오프셋은 사용자를 표현하는데, 사용자 1은 오프셋 1, 사용자 30은 오프셋 30을 나타내며 나머지는 동일하다.
비트맵 접근 방식
사용자가 웹페이지를 방문하면 사용자 ID에 해당하는 비트에 1의 값을 주고, 사용자가 방문하지 않으면 0의 값을 저장하는 구성
SETBIT 커맨드는 비트맵 오프셋에 값을 저장하기 위해 사용되며 값은 1또는 0을 받는다.
SETBIT 커맨드 실행 시 비트맵이 존재하지 않으면 해당 커맨드가 비트맵을 생성한다.

이 코드에서, 사용자 10과 15는 2015-01-01에 웹사이트를 방문했고, 사용자 10과 11은 2015-01-02에 웹사이트를 방문했다.
GETBIT 커맨드는 비트맵 오프셋 값을 리턴한다.
다음 예제에서 2015-01-01에 사용자 10이 방문했는지 확인한 후, 2015-01-02에 사용자 15가 방문했는지를 확인한다.

BITCOUNT 커맨드는 비트맵에 1로 표시된 모든 비트의 개수를 리턴한다.
예제에서 특정 날짜에 웹사이트를 방문한 사용자 수를 리턴한다.

BITOP 커맨드는 대상 키, 비트 연산, 해당 연산에 적용하고 결과를 대상 키에 저장할 키 목록이 필요하다.
BITOP 커맨드에서 사용할 수 있는 비트 연산은 OR, AND, XOR, NOT이다.
다음 예제는 특정 일에 웹사이트를 방문한 사용자가 몇 명인지 알기 위해 BITOP OR을 사용한다.

해당 예제는 방문을 한 번만 저장한다.
동일 날짜에 동일 사용자가 계속 방문한다하더라도 계산하지 않고 한 번만 저장한다.
전체 방문 숫자를 알고 싶다면, 별도 카운터와 같은 문자열을 사용해야 한다.
매번 방문이 발생할 때마다, 해당 카운터에서 INCR을 실행해야 한다.
💚 하이퍼로그로그
하이퍼로그로그는 레디스의 실제 데이터 타입이 아니다.
하이퍼로그로그는 개념적으로는 알고리즘이다.
셋에 존재하는 고유 엘리먼트 개수를 아주 좋은 근사치로 제공하기 위해 확률화를 사용하는 알고리즘이다.
하나의 키당 아주 작은 메모리(최대 12KB의 메모리)를 사용하며, 항상 O(1)로만 동작하기 때문에 매력적이다.
기술적으로 하이퍼로그로그가 실제 데이터타입이 아닐지라도, 레디스는 하이퍼로그로그 알고리즘을 사용해 셋의 개수를 계산하기 위한 문자열을 제어하는 커맨드를 제공하기 때문에 데이터 타입처럼 다루는 것이다.
하이퍼로그로그 알고리즘은 100%의 정확도를 보장하지 않는 확률적인 알고리즘이다.
하이퍼로그로그의 레디스 구현은 0.081퍼센트의 표준오차를 가진다.
이론상 셀 수 있는 셋의 개수 제한은 사실상 없다.
참고
최초 소개 논문
(Philippe Flajolet 외 3인의 공동 논문 'The analysis of a near-optimal cardinality estimation algorithm')
https://hal.archives-ouvertes.fr/hal-00406166/
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
This extended abstract describes and analyses a near-optimal probabilistic algorithm, HYPERLOGLOG, dedicated to estimating the number of \emphdistinct elements (the cardinality) of very large data ensembles. Using an auxiliary memory of m units (typically,
hal.inria.fr
주요 커맨드
- PFADD
- PFCOUNT
- PFMERGE
PF접두어는 하이퍼로그로그를 만든 Philippe Flajolet을 기념해 만들어졌다.
종종 고유 개수를 계산하기 위해, 현재 계산 중인 셋의 엘리먼트 개수에 비례하는 메모리가 있어야 한다.
하이퍼로그로그는 좋은 성능, 낮은 계산 비용, 적은 메모리 양으로 해당 문제를 해결한다.
그러나 하이퍼로그로그는 100퍼센트 정확하지 않음을 기억하는 것이 중요하다.
그럼에도 불구하고 일부 상황에서는 99.19퍼센트 정도라면 괜찮을 수 있다.
사용 예시
✨ 웹사이트의 고유 방문자 수 계산
✨ 특정 날짜 또는 시간에 웹사이트에서 검색한 고유 키워드 개수 계산
✨ 사용자가 사용한 고유 해시태그 개수 계산
✨ 책에 나오는 고유 단어 개수 계산
고유 방문자 수 계산: 하이퍼로그로그 vs. 셋
시간당 특정 웹사이트의 고유 방문자 수를 계산하면서 하이퍼로그로그와 셋이 각각 얼마나 메모리를 사용하는지 확인한다.
시나리오
- 특정 웹사이트는 시간당 평균 100,000명의 고유 방문자 수가 있다.
- 웹페이지를 방문한 각 사용자는 32바이트 문자열로 표현되는 UUID(Universally Unique Identifier)로 식별된다.
모든 고유 방문자 수를 저장하기 위해 하루의 모든 시간에 대해 레디스 키를 생성한다.
즉 하루에 24개의 키가 있고 한 달에는 720키(24*30)가 존재한다.
하이퍼로그로그는 100,000명의 고유 방문자 수를 저장하기 위해 12KB까지 사용한다.
한편 셋은 각 UUID가 32바이트씩인 100,000UUID를 저장하기 위해 3.2MB를 사용한다.
각 데이터 타입별로 얼마만큼의 메모리가 필요한지 보여준다.
| 데이터 타입 | 한 시간 동안 사용할 메모리 | 하루 동안 사용할 메모리 | 한 달 동안 사용할 메모리 |
| 하이퍼로그로그 | 12KB | 12KB * 24 = 288KB | 288KB * 30 = 8.4MB |
| 셋 | 32bytes * 100000 = 3.2MB | 3.2MB * 24 = 76.8MB | 76.8MB * 30 = 2.25GB |
이런 상황에서는 하이퍼로그로그가 셋보다 더 적합하다.
PFADD 커맨드는 하나 이상의 문자열 하이퍼로그로그에 추가한다.
PFADD 커맨드는 하이퍼로그로그의 개수(Cardinality)가 변경되면 1을 리턴하고, 변경되지 않으면 0을 리턴
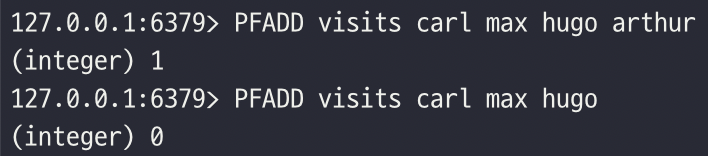
PFCOUNT 커맨드는 하나 이상의 키를 매개변수로 받는다.
PFCOUNT 커맨드에 한 매개 변수를 명세하면, 근사치 개수를 리턴한다.
다중 키를 명세하면 모든 고유 엘리먼트의 개수를 계산하기 위해 근사치 개수로 리턴한다.

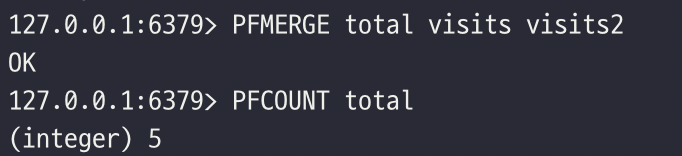
PFMERGE 커맨드는 대상 키와 하나 이상의 하이퍼로그로그 키를 매개변수로 받아야 한다.
PFMERGE 커맨드는 명세한 모든 하이퍼로그로그를 병합하고, 병합한 결과를 대상 키에 저장한다.
'TIL💡 > Database' 카테고리의 다른 글
| [Redis] 데이터 타입의 최적화 (0) | 2022.02.27 |
|---|---|
| [Redis] 다양한 커맨드와 기능 소개 (0) | 2022.02.27 |
| [Redis] Redis 학습 및 데이터 타입 실습1 (0) | 2022.02.26 |
| [SQL Server] Transaction (0) | 2022.02.12 |
| [SQL Server] Lock (0) | 2022.02.08 |