2022. 10. 15. 01:00ㆍTIL💡/Database
MongoDB는여러 유형의 인덱스를 가지고 있다. 5.3부터는 Clutstered Index도 지원한다. Clustered Index의 장점 중 하나인 랜덤 액세스 없이 레코드를 읽는 기능은 빠른 range scan 속도를 자랑한다. 이외에도 다양한 인덱스가 존재한다.
참고: https://www.mongodb.com/docs/manual/indexes/
그 중에서 MongoDB는 기본적으로 B-Tree를 기본 인덱스 구조로 지향한다.

B-Tree의 인덱스 구조가 다른 인덱스의 구조에 비해 다음과 같은 장점이 있다.
1. 각 리프 노드가 동일한 깊이에 있기 때문에 균등한 응답속도를 보장한다.
하나의 컬렉션 내의 도큐먼트가 3~4개의 I/O 이상으로 떨어져 있지 않다.
2. B-Tree는 깊이가 최대 4개(헤더 블록 1개, 브랜치 블록 2개, 리프 블록 1개)이므로 대규모 컬렉션에 대해 우수한 성능을 제공한다. 일반적으로 문서를 찾는 데 4개 이상의 I/O가 필요하지 않다. 실제로 헤더 블록은 거의 항상 미리 메모리에 로드되고, 브랜치 블록들도 일반적으로 메모리에 로드되기 때문에 실제 디스크 읽기 수는 일반적으로 1~2개에 불과하다.
3. B-Tree 인덱스는 정확하고 빠른 조회뿐만 아니라 range scan query를 지원한다.
이것이 가능한 이유는 이전 리프 블록과 다음 리프 블록에 대한 링크 덕분이다.
각각의 노드들은 노드 하나에 한 개의 데이터가 아닌 복수의 데이터를 저장하는 Bucket이라는 저장소를 이용한다.
그렇기 때문에 하나의 노드에 많은 데이터를 담을 수 있으며, 트리의 깊이를 낮추고 Hit rate를 높일 수 있다.
Bucket 안에 포함된 데이터는 B-Tree 구조는 아니며, 따라서 Bucket 안의 데이터를 검색할 때는 순차 루프를 필요로 한다.
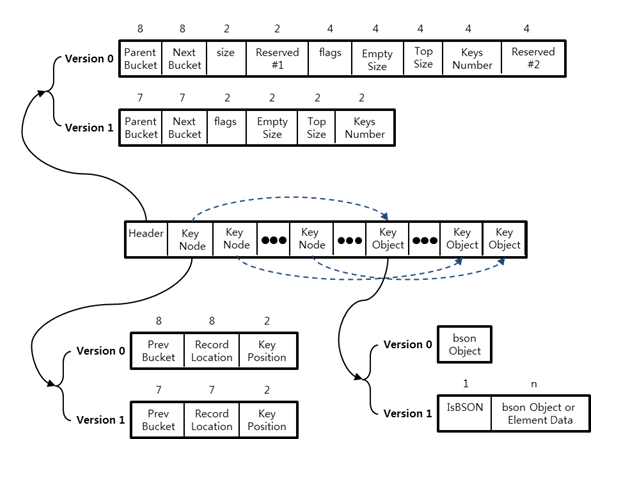
2010년 4월 이전의 인덱스 구조는 Version 0, 이후에는 Version 1 구조를 사용한다.
두 개의 버전이 공존하는 이유는 데이터 파일에 대한 호환성을 보장하기 위함이다.
Version 0에서는 B-Tree 노드의 헤더 영역과 인덱스의 데이터를 저장하기 위해 BSON 객체를 직접 사용하였지만, vErsion 1에서는 인덱스의 데이터를 직접 저장하는 방법으로 바꿔 메모리 효율성을 증가시켰다.
MongoDB의 인덱스는 다른 NoSQL과 달리 RDBMS와 같은 Secondary Index를 지원하며, 복합 인덱스와 같은 유연한 특성을 가지고 있다.
하지만 MongoDB의 인덱스는 Bucket에 Key값을 저장하기 때문에, 도큐먼트에 저장된 데이터와 중복 저장되는 단점이 있고, 인덱스를 위한 입출력 기술이 운영체제가 제공하는 Page Fault 방식을 같이 사용하기 때문에 메모리가 부족한 시스템에서는 오히려 검색 속도가 저하되는 단점이 있다. 적은 메모리를 사용할 경우 인덱스를 사용하지 않는 편이 검색 시간을 단축하기도 한다.
또, MongoDB는 Schema-Free 데이터베이스라고 말한다. 이것은 컬렉션에 대해서는 맞는 이야기이지만, 인덱스에서는 맞지 않는 이야기이다.
인덱스는 내부적으로 별도의 스키마를 가지고 있으며, 각 인덱스들이 어떤 인덱스인지, 인덱스를 구성하는 필드는 어떤 것인지에 대한 메타 정보를 가지고 있다.
참고
https://rastalion.me/mongodb-index-1-architecture/
MongoDB Index #.1 Architecture - RastaLion's IT Blog
MongoDB Index #.1 - Architecture, MongoDB의 인덱스 구조, MongoDB의 인덱스 동작 방식, B-Tree 인덱스에 대한 이해, MongoDB의 인덱스 사용시 주의사항
rastalion.me
'TIL💡 > Database' 카테고리의 다른 글
| [MySQL] 597. Friend Requests I: Overall Acceptance Rate (0) | 2022.11.26 |
|---|---|
| [MySQL] 596. Classes More Than 5 Students(GROUP BY, HAVING) (0) | 2022.11.26 |
| [Python] Celery로 비동기 실시간 데이터 적재 및 분석 처리 (0) | 2022.09.09 |
| [MongoDB] 소개와 설명 (0) | 2022.06.25 |
| SQL 가독성을 높이는 다섯 가지 사소한 습관 (0) | 2022.06.10 |